





When we first adopted dbt as our standard data transformation tool in 2019, it was not because of how advanced the technology was. Instead, it was its simplicity and developer experience that made it a great choice compared to bloated ETL tools or developing our own ELT tooling.
I’m not alone when I say that dbt is the number one tool in the data stack that I wish I had developed first. Its software engineering approach to data is so powerful that we, along with thousands of data teams worldwide, can scale our analytics engineering practice much more efficiently than we could with any other product available.
What the SDF Acquisition Means for dbt’s Evolution and Competitive Edge
So, why is everyone so excited about the recently announced acquisition and upcoming integration of SDF, “a high-performance toolchain for SQL development”, into dbt? Does it make a difference for the Analytics Engineer who loves dbt for its simplicity? As it turns out, it does. And for a few different reasons.
First, as dbt’s use cases grew more complex, it became clear that some design choices on dbt’s inner workings hindered some of the developer experience. The most important point is that dbt is not a SQL parser. In simpler terms, it does not understand SQL.
dbt utilizes a templating language to add dbt-specific logic to the plain SQL code that users write. While I won’t go too deep on this (you can read the dbt Labs official announcement here with detailed explanations), not having a parser means that dbt could not optimize SQL code without running it on the database, for some large projects that could take dozens of minutes of wasted engineering time for each run (or hours per week for each developer).
Additionally, it meant that data teams with complex, multi-platform architectures had to write intricate macros to handle database-specific SQL dialects. Similarly, database migrations require a lot more work than they would when the SDF parser is fully integrated into dbt.
Second, there is a competitive push here from other companies that offered a dbt-like tool with SQL parsers, so this is also a defensive move from dbt Labs. With a high-performing SQL parser, a large community of users, and rapidly growing enterprise adoption, dbt is almost unbeatable as the de facto standard in data transformation.
The Real AI Play: Why dbt’s Future Is About More Than Just Faster SQL
Finally, there is AI. SDF enables dbt developers to utilize IntelliSense-style SQL suggestions, similar to type-ahead functionality in IDEs, which is standard for other programming languages. This feature provides auto-suggestions for table and column names as users type.
Also, it can interpret SQL locally and identify SQL semantics, making dbt much safer for GenAI-enhanced data pipeline development. That means developers can use advanced LLMs to write dbt models while relying on SDF’s advanced parsing to identify potential issues, such as hallucinations, data quality problems, or data security concerns, before any query is sent to the database.
More importantly, with the dbt semantic layer, dbt will likely be the tool that allows users to interact with data in natural language while maintaining semantics and governance, which many advertise but rarely achieve.
In other words, while SDF can substantially improve dbt development, there is an even more significant opportunity if dbt can prove itself as the AI-powered semantic layer for analytics. Since running a semantic layer requires a server, this approach could open a whole new space for dbt Cloud, focusing on business users instead of analytics engineers.
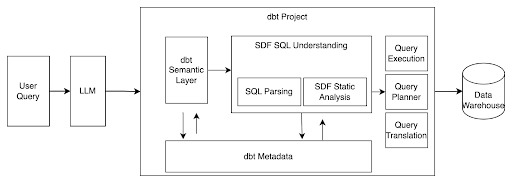
While it’s still unclear exactly how the integration between dbt and SDF will be implemented in the codebase (with differences announced between dbt core and cloud), Tristan Handy has ensured that all dbt users will benefit from these improvements. In any case, we can expect dbt to establish itself as an even stronger data transformation engine for the AI era.




